Project Description
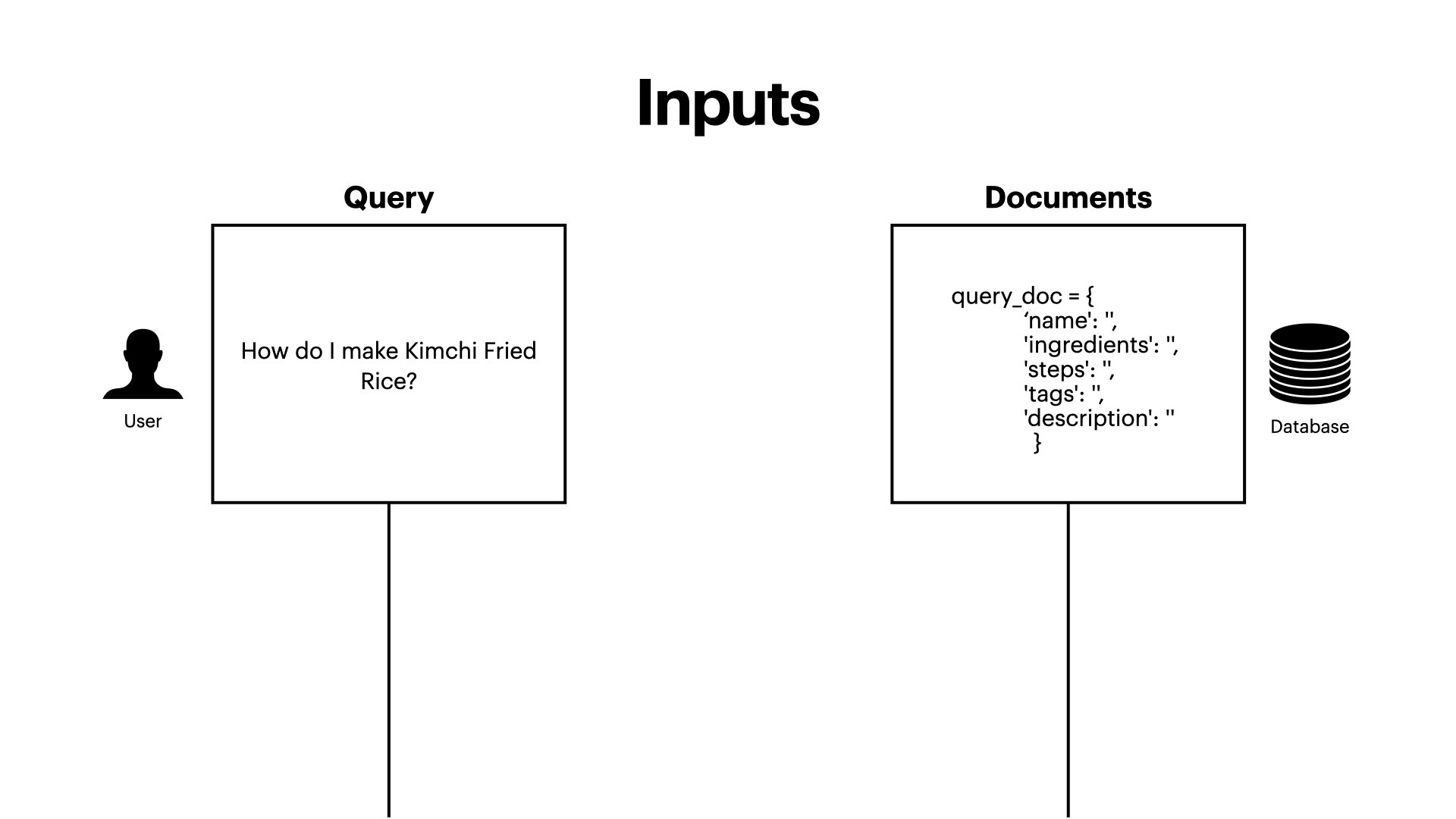
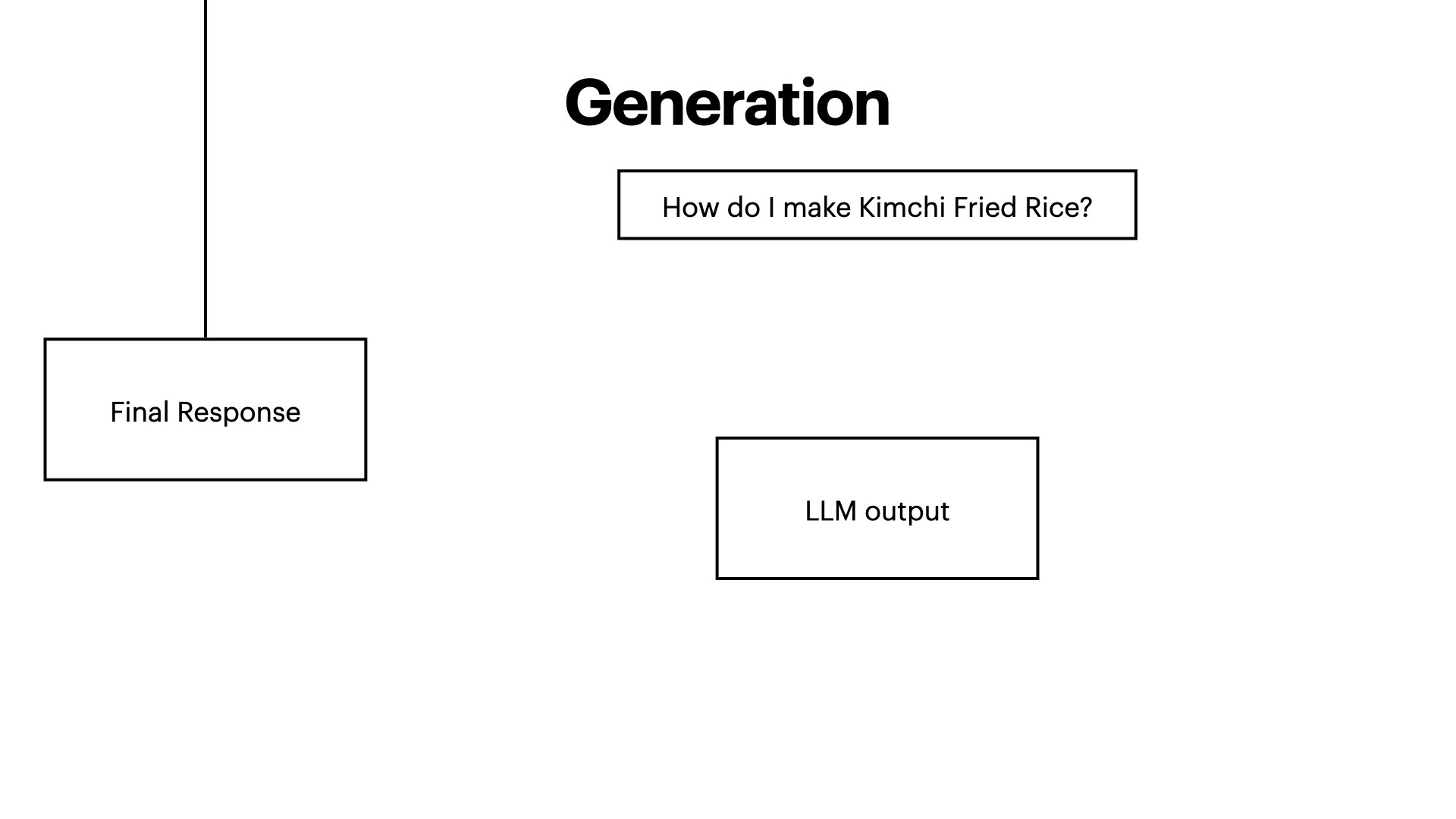
Retrieval-Augmented Generation (RAG) is a technique where a model retrieves relevant external information (in this case, wikipedia recipe datasets) and then uses it to generate more accurate, up-to-date, and context-aware answers. As LLM's face limitations in accessing and utilising up-to-date or domain-specific information, RAG offers a solution to enhance their contextual understanding and response accuracy This project implements a RAG pipeline, aiming to explore and analyse the advantages and disadvantages of Word-level TF-IDF retrieval.
Key Components
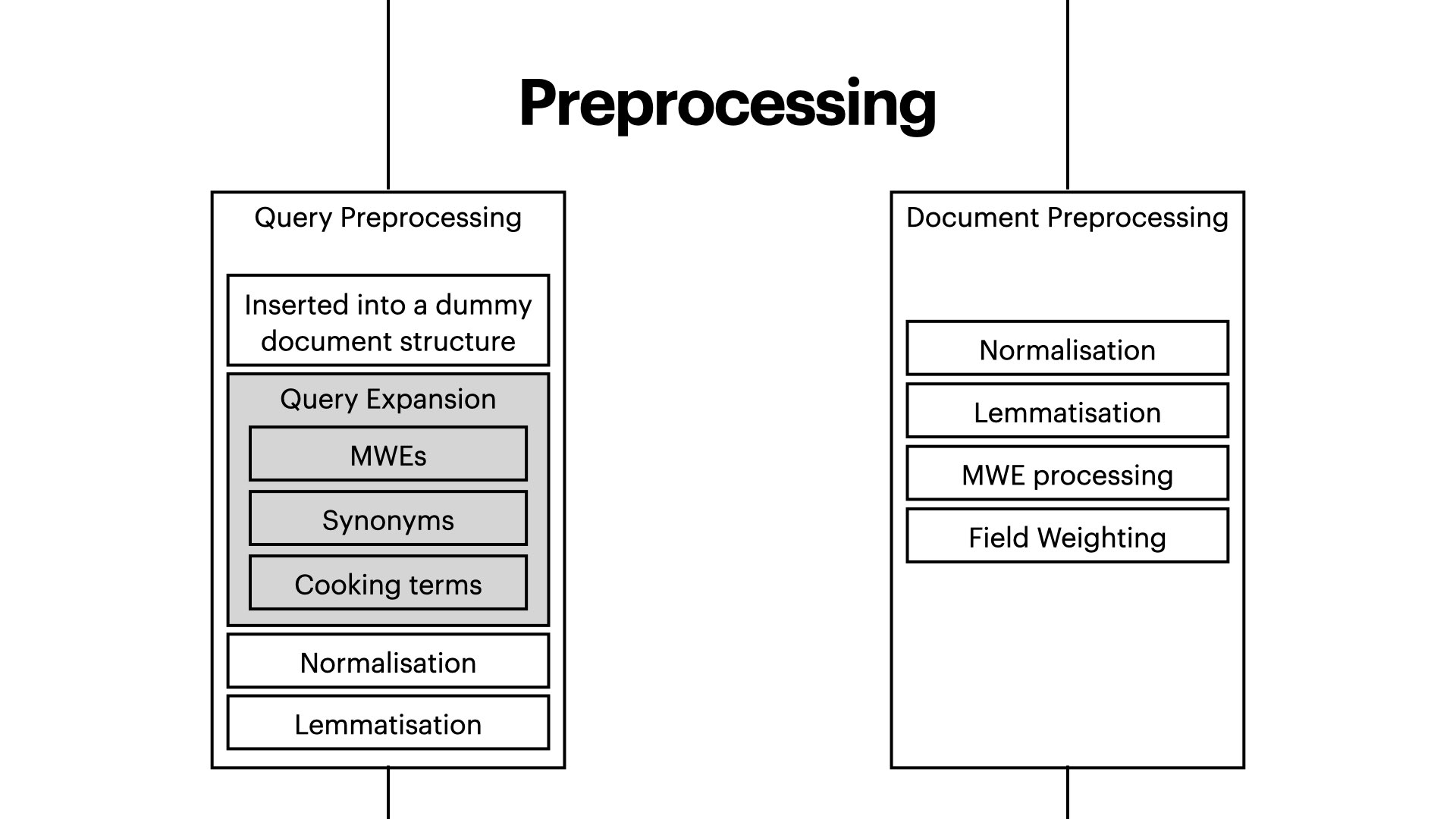
- Data Preprocessing: Query Explansion, text normalisation, lemmatisation, and document indexing
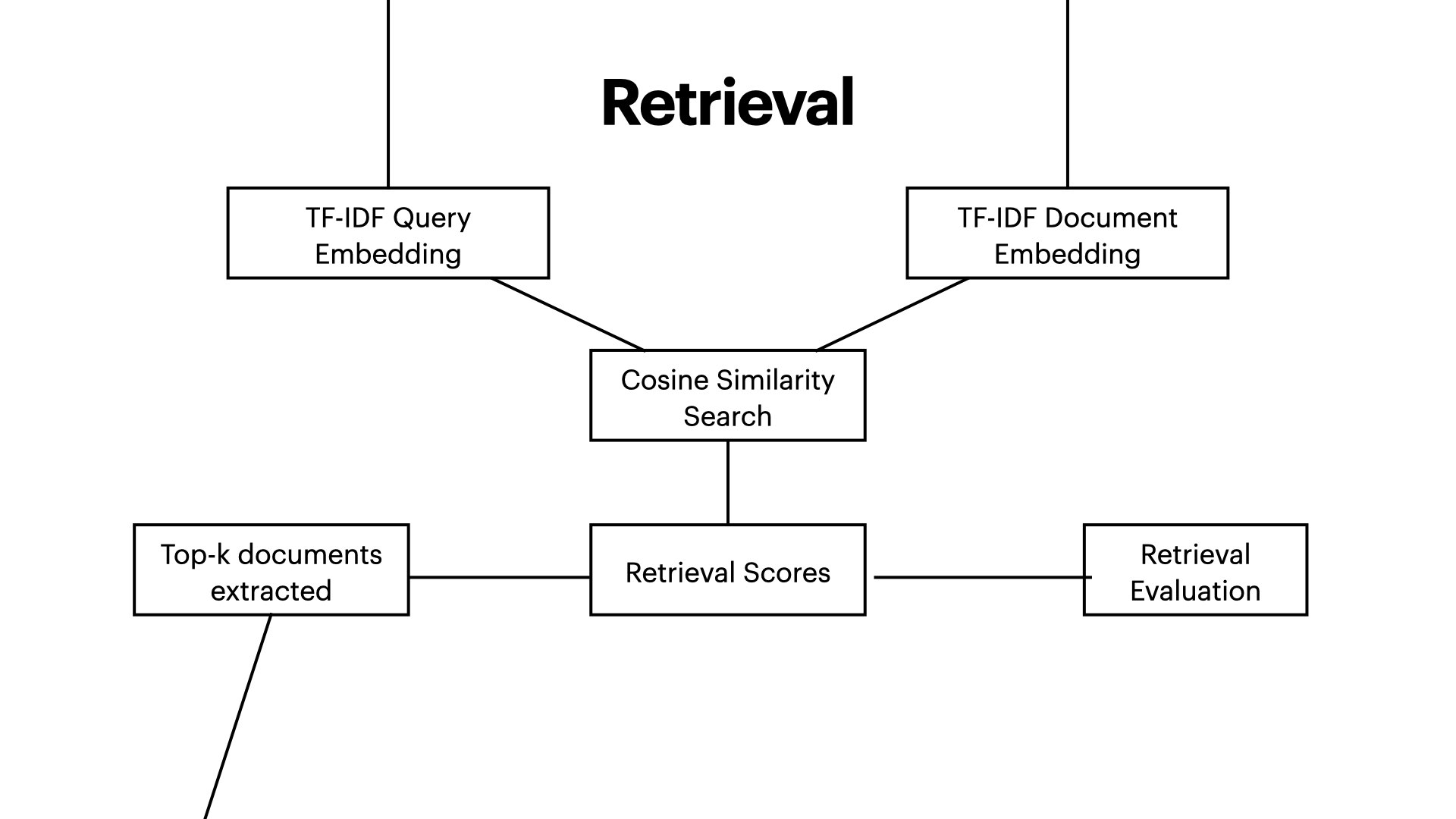
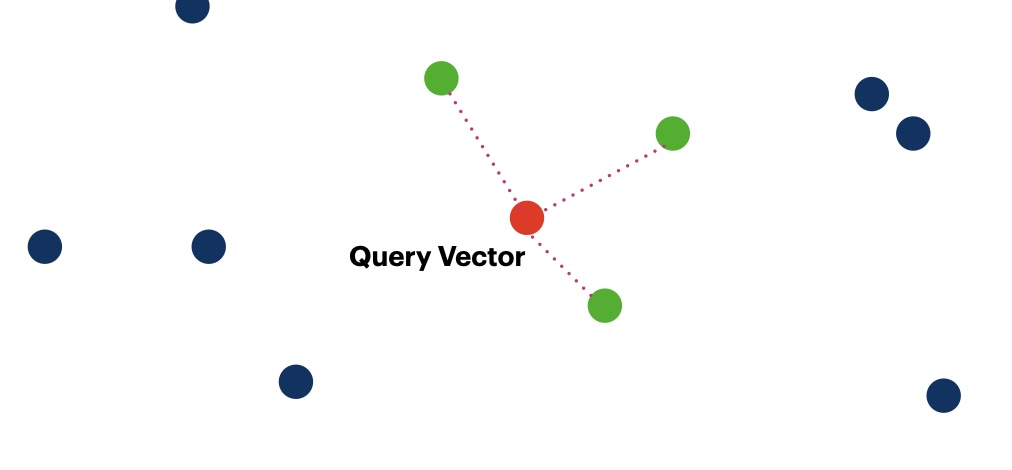
- TF-IDF Retrieval: Term frequency-inverse document frequency scoring for relevant document retrieval
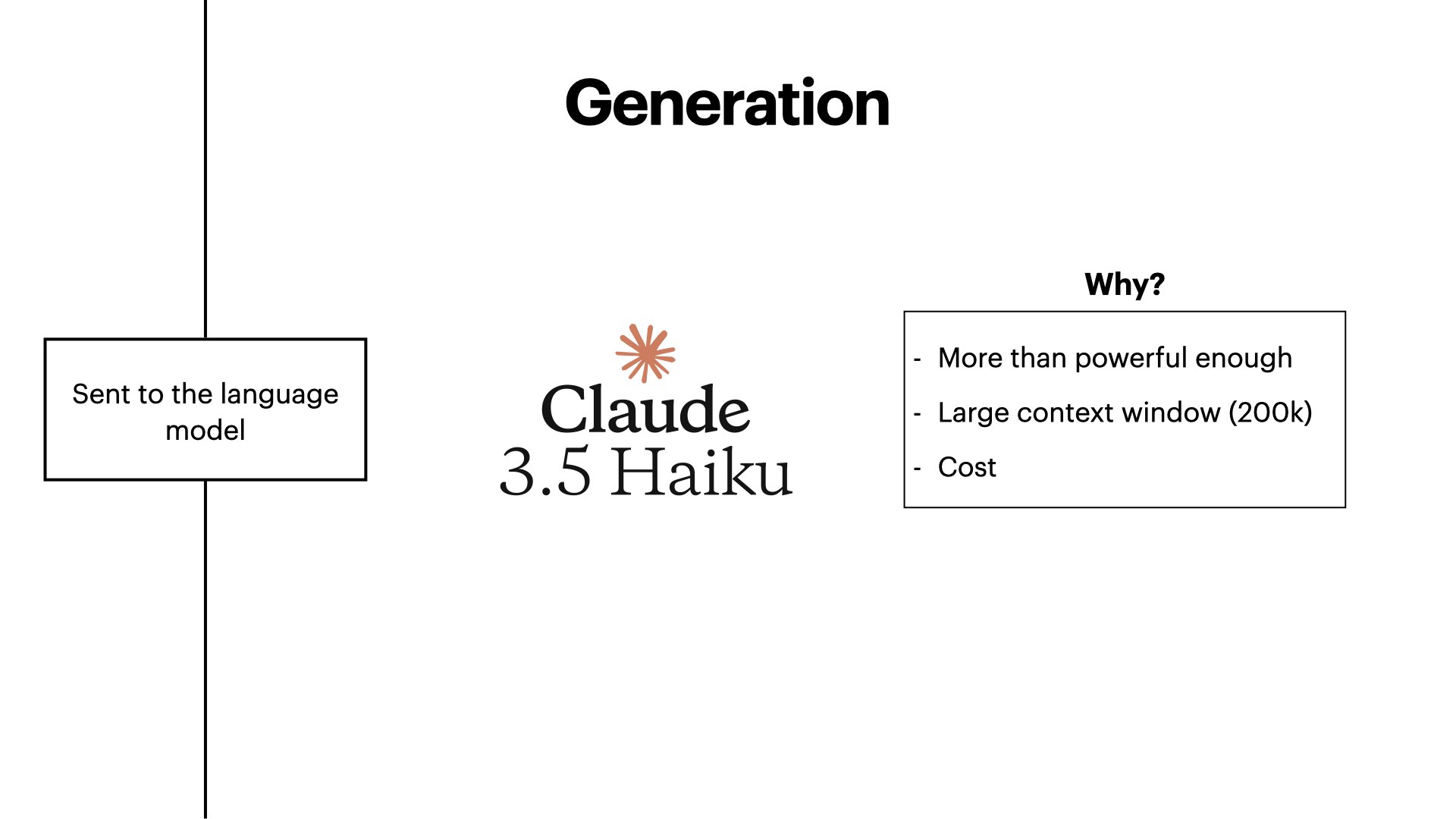
- Claude API Integration: Leveraging advanced language models for context-aware response generation
- Evaluation: Precision, Recall, F1 score and MAP to ensure robust evaluation
Project Presentation
Below are a few slide exerpts, describing a high level overview of this project.